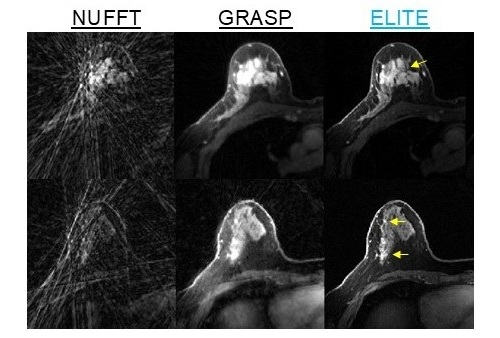
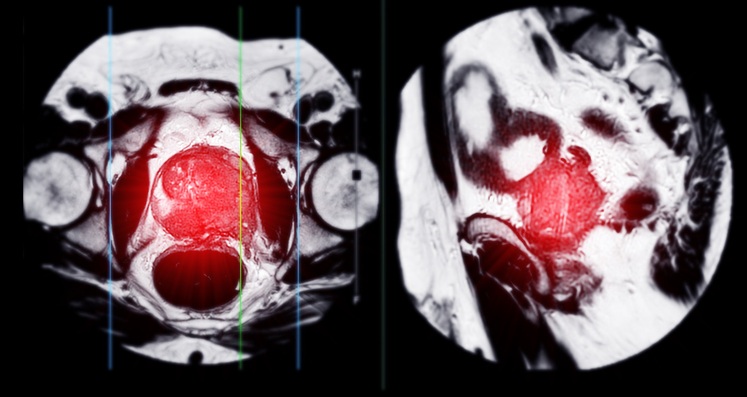
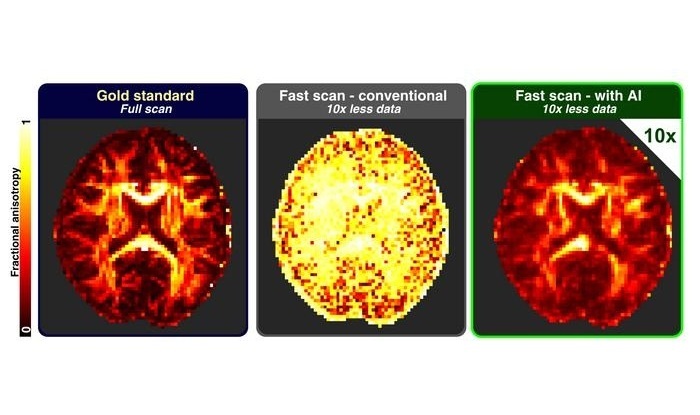
Modelo de IA alcanza precisión a nivel clínico experto al analizar imágenes por resonancia magnética complejas y escaneos médicas 3D
Actualizado el 18 Oct 2024
Las redes neuronales artificiales se entrenan realizando cálculos repetidos sobre grandes conjuntos de datos que han sido cuidadosamente examinados y etiquetados por expertos clínicos. Mientras que las imágenes 2D estándar muestran longitud y anchura, las tecnologías de imágenes 3D introducen profundidad, creando imágenes "volumétricas" que requieren más tiempo, habilidad y atención para la interpretación experta. Por ejemplo, una exploración de imágenes de retina 3D puede constar de casi 100 imágenes 2D, lo que requiere varios minutos de examen minucioso por parte de un especialista altamente capacitado para identificar biomarcadores sutiles de la enfermedad, como medir el volumen de una hinchazón anatómica. Ahora, los investigadores han desarrollado un marco de aprendizaje profundo que se entrena rápidamente para analizar y diagnosticar automáticamente las resonancias magnéticas y otras imágenes médicas 3D, logrando una precisión comparable a la de los expertos médicos, pero en una fracción del tiempo.
A diferencia de otros modelos en desarrollo para el análisis de imágenes en 3D, el nuevo marco creado por investigadores de UCLA (Los Ángeles, CA, EUA) es muy adaptable a diversas modalidades de obtención de imágenes. Se ha estudiado con exploraciones de retina en 3D (tomografía de coherencia óptica) para biomarcadores de riesgo de enfermedades, videos de ultrasonidos para la evaluación de la función cardíaca, exploraciones de resonancia magnética en 3D para evaluar la gravedad de la enfermedad hepática y exploraciones de TC en 3D para la detección de neoplasias malignas en nódulos torácicos. En un artículo publicado en la revista Nature Biomedical Engineering, los investigadores destacan las amplias capacidades del sistema, lo que sugiere que podría ser valioso en muchos otros entornos clínicos. Se planean estudios adicionales para explorar más a fondo sus aplicaciones.
")
El modelo de la UCLA, llamado SLIViT (SLice Integration by Vision Transformer), presenta una combinación única de dos componentes de inteligencia artificial y un enfoque de aprendizaje especializado. Según los investigadores, esta combinación le permite predecir con precisión los factores de riesgo de enfermedades a partir de exploraciones médicas en múltiples modalidades volumétricas, incluso con conjuntos de datos etiquetados de tamaño moderado. La anotación automatizada de SLIViT podría beneficiar tanto a los pacientes como a los médicos al mejorar la eficiencia y la puntualidad del diagnóstico, al tiempo que avanza en la investigación médica al reducir los costos de adquisición de datos y acortar el tiempo necesario para la recopilación de datos. Además, establece un modelo fundamental que puede acelerar el desarrollo de futuros modelos predictivos.
“SLIViT supera el cuello de botella del tamaño del conjunto de datos de entrenamiento aprovechando el 'conocimiento médico' previo del dominio 2D más accesible”, dijo Berkin Durmus, estudiante de doctorado de la UCLA y coautor principal del artículo. “Mostramos que SLIViT, a pesar de ser un modelo genérico, logra consistentemente un rendimiento significativamente mejor en comparación con los modelos de vanguardia específicos del dominio. Tiene potencial de aplicabilidad clínica, igualando la precisión de la experiencia manual de los especialistas clínicos al tiempo que reduce el tiempo en un factor de 5.000. Y a diferencia de otros métodos, SLIViT es lo suficientemente flexible y robusto como para trabajar con conjuntos de datos clínicos que no siempre están en perfecto orden”.